
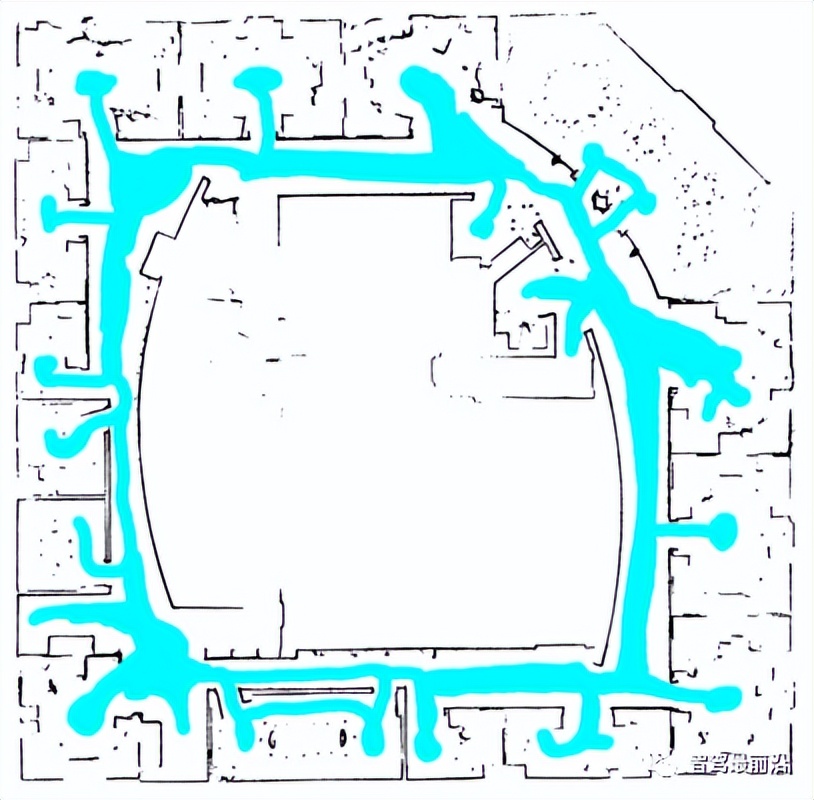

图6 2D点云配准技术(左)2D SLAM建图(中)2D激光定位(右)
2.2. 3D激光定位技术发展现状
3D激光定位技术的发展相对滞后于2D,其中的原因主要有两点:3D激光雷达,3D SLAM算法。随着以velodyne公司为代表的激光雷达厂商的发展和3D激光雷达生产工艺的成熟和成本的下探,以及以LOAM系为代表的3D SLAM算法突飞猛进的发展,3D激光SLAM技术开始实现突破,并直接促成了3D激光定位技术的大规模落地。
常见的机械式3D激光雷达方案如下图所示,在3D激光雷达内部集成了多组激光发射器和接收器,它们在电机的驱动下360度循环旋转,实现对环境的扫描,每次扫描将返回一帧完整的点云。近年来,固态激光雷达也获得了快速的发展并开始投入商用,国内如览沃、速腾聚创、禾赛激光等厂商也初步推出了固态激光雷达产品。固态激光雷达的最大优势在于成本,随着产量的提升,成本预计将下探到同等机械激光雷达成本的十分之一。但固态雷达在点云形态上与机械激光雷达不同,通常FoV(视场角)较小,类似于深度相机。基于固态雷达的SLAM技术目前已经得到了发展,但仍有进一步提升的空间。同样受限于FoV太小,基于固态激光雷达的定位技术目前还不够成熟。
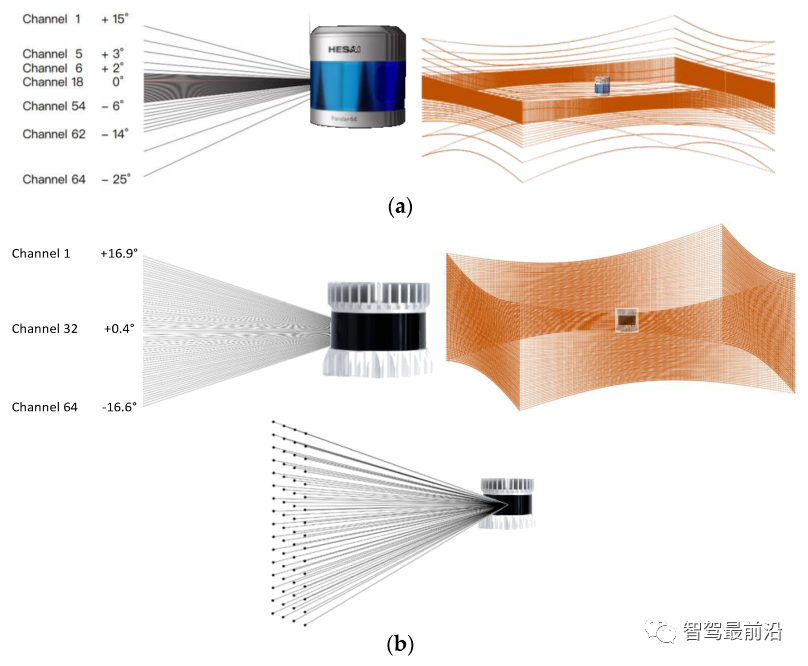
图7 传统旋转式机械激光雷达及其典型点云图

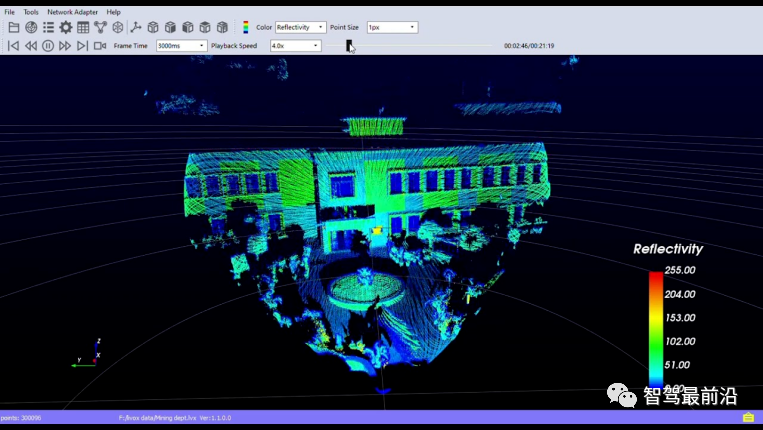
图8 固态激光雷达及其典型点云图
3D SLAM算法的爆发性发展可以追随到2014年由Ji Zhang发表的论文《LOAM: Lidar Odometry and Mapping in Real-time》,该论文首次提出了基于边缘特征和平面特征的点云配准算法,实现了兼顾速度和精度的激光SLAM建图,该方案简称为LOAM。其提出的特征点配准方法启发了大量后续研究,代表性的有LeGO-LOAM,LIO-SAM等。同时,随着算力和算法的进步,基于ICP(Iterative Closest Point, 迭代最近点)的一些衍生型点云配准算法(如G-ICP,VGICP)等也得到了发展。这些点云配准技术的进步,结合多传感器融合算法的进步(滤波和非线性优化,松耦合和紧耦合),实现了更高阶的3D SLAM技术,代表性开源方案有FAST-LIO2,Super-Odometry等。

图9 卫星图及算法所建点云图

图10 FAST-LIO2算法建图
3D定位技术与SLAM技术的发展息息相关,在机器人领域,3D定位功能作为SLAM的应用之一出现;而在自动驾驶领域,3D定位则未必需要建图(存在关于是否需要高精地图的技术路线之争)。3D定位技术同样非常强调多传感器融合,通常至少需要融合3D激光雷达和IMU,其它的传感器还包括轮式里程计、GNSS等。虽然有一些开源框架也支持定位模式,比如HDL-Graph-SLAM,Cartographer(3D)等,但并不能达到直接商用落地的要求。综合来讲,各个机器人公司的3D定位技术都会在开源算法的基础上进行开发,或直接借助开源算法框架,或借助开源技术和公开论文全栈自研。

图11 3D激光定位
视觉定位技术发展现状
定位技术往往伴随着传感器技术的进步而发展。比如,2D激光雷达使定位技术的鲁棒性第一次达到商用级别,3D雷达则进一步将其推广到更广阔的应用场景,比如自动驾驶。在过去数十年内,视觉传感器发展迅速,目前基于视觉定位的技术也达到商用水平,广泛地应用在VR、AR和基于视觉定位的移动机器人导航上。
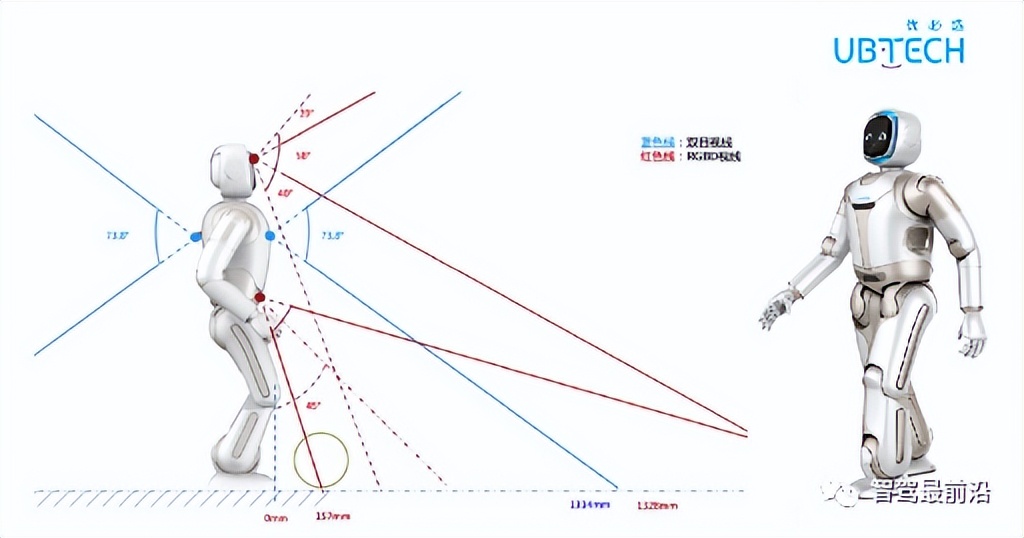
图12 视觉SLAM运用在优必选服务机器人walker上
视觉SLAM算法可以根据传感器类型被分为三类:纯视觉SLAM、RGB-DSLAM和视觉惯SLAM。纯视觉算法根据追踪的目标不同又被划分为基于特征的(feature-based)和直接(direct)法。其中,前者通过最小化空间重投影误差来优化位姿计算,对弱纹理场景敏感且计算量大;后者通过最小化像素的光度误差来优化位姿,但依赖准确的初始值。
基于RGB-D相机的SLAM系统能直接提供深度图,形成稠密地图,往往被用在三维重建任务上,微软的KineticFusion 算法就是第一个具有实时性的重建算法;近年,用于机器人感知的语义SLAM问题也广泛采用RGB-D相机的深度图作为建图输入,如麻省理工大学的Kimera系统。视觉惯导SLAM,即使用相机和IMU的视觉SLAM方案,一直是视觉定位领域的佼佼者,在广泛的场景下得到应用(如,VR、无人机等)。
视觉惯导SLAM因相机和IMU具有信息互补的特性和低廉的价格而广泛受到关注:相机在低速状态下提供丰富的信息,但对场景尺度估计精度低,在光照变化和运动模糊时鲁棒性降低;IMU对场景变化鲁棒且具有高采样率,但伴有传感器偏置。对于通过传感器融合来提升SLAM系统精度的方案来说,IMU和相机的组合是在体积、重量、耗电和成本达到最优解的6自由度位姿估计器。

图13 视觉惯导SLAM在大疆无人机上的应用
相较于基于激光雷达的SLAM算法,纯视觉算法由于视野、尺度估计等硬件极限问题,目前精度和鲁棒性上尚无法和雷达达到同一水准。但其通过同IMU和主动结构光发射硬件的结合,目前已实现同水准的精度。同激光SLAM一样,视觉也面临当前SLAM领域的未解难题:软硬系统失效的检测和恢复、自动的参数调优、尺度地图的重定位和有限计算和存储资源下的Life-long SLAM。不同的是,视觉SLAM同时也蕴藏着解决这些问题丰富的机遇。图像相较激光具有丰富的纹理信息,通过深度学习能高效习得场景特征,在重定位问题上被广泛研究和验证(如,Patch-NetVLAD)。

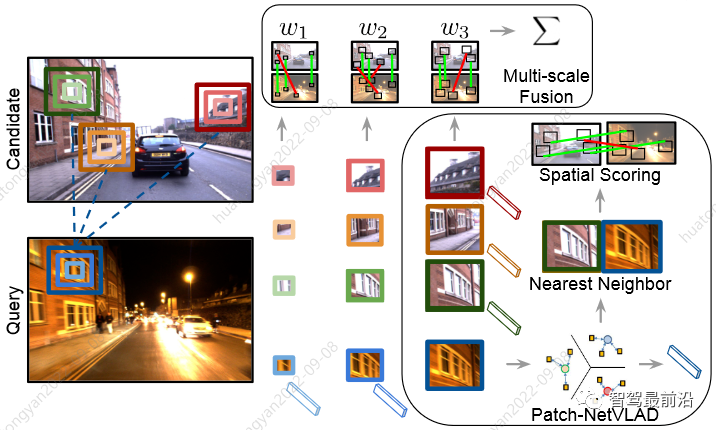
图14 视觉用于解决光照和场景物体变化的重定位问题(Patch-NetVLAD)
而在life-longSLAM问题中,我们需要解决两大问题:如何判断是否更新地图,如何高效存储、表征和更新地图。传统激光雷达的点云地图和视觉的TSDF面元对存储和计算资源要求都极高,而近年发展起来基于视觉的高层级几何理解和物体语义为这些问题提供了新的解决思路。图像丰富的纹理信息使提取表征场景几何特征的点、线、面元素较易提取,这不仅使帧间的特征追踪更加稳定,还引入了鲁棒、紧凑的场景信息表达,使长周期的存储和更新计算变得可行。同时,视觉可以提取场景中物体级别的语义标签,这使得地图的更新标准可解释性和召回率显著提升,让全生命周期的语义地图维护更加精准高效。
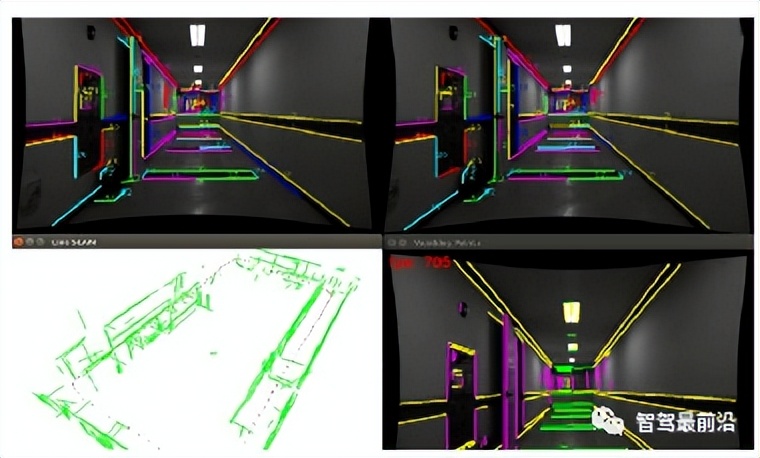
图15 旷视科技的Struct SLAM
转载自深蓝AI,文中观点仅供分享交流,不代表本公众号立场,如涉及版权等问题,请您告知,我们将及时处理。




































